The data layer for internet-scale crawling.
The crawling platform enterprises run entirely inside their own infrastructure. The scrape API and curated datasets are still here when all you need is data.
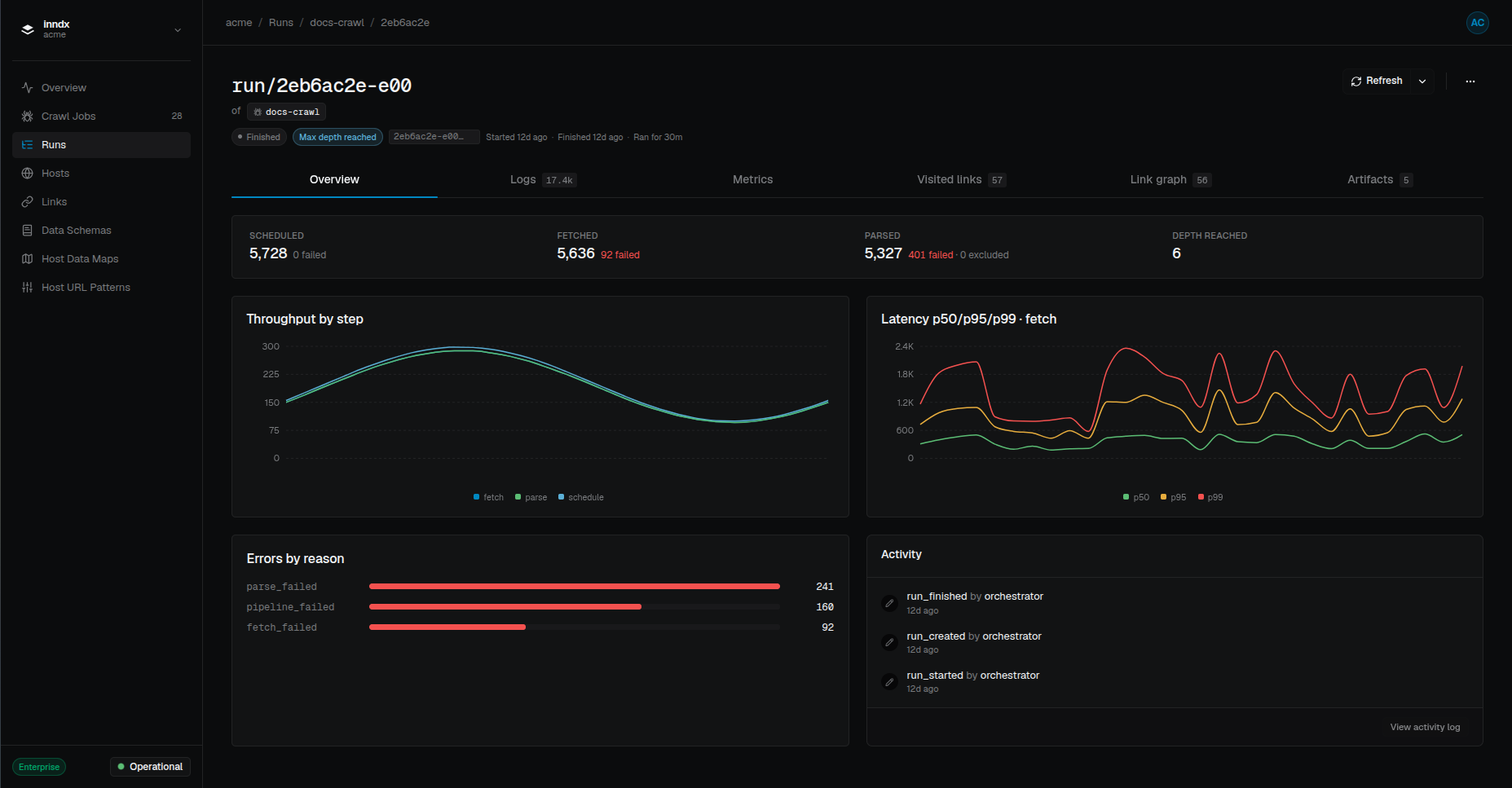
One dashboard, every stage of the crawl.
Define the job, watch it run, and see the data roll in, all from inside your own environment.
Built for the teams running it.
A platform shaped around the people who operate it day to day, not just the API that fronts it.
Platform & infra teams
Run the platform on infrastructure you already manage. Deploy it alongside the systems your team owns and scale it the same way.
Data & ML teams
Pull clean, model-ready content at scale, or reach for the scrape API directly for one-off jobs.
Security & compliance
Crawled data stays inside your environment under your own access controls, end to end.
Engineering leadership
One platform to own, built to scale horizontally as throughput needs grow.
Hit the scrape API directly. URL in, clean content out.
The same engine behind the platform, exposed as a single endpoint. Point it at any URL and get back clean, model-ready content in Markdown, HTML, or other formats. Pay per call with a wallet over MPP, no account required.
# Launching the new platform
*Jordan Avery · 8 min read*
Clean, readable content. Navigation, ads, and boilerplate stripped before it reaches your pipeline.
## What changed
Every stage of the crawl now runs through a single orchestrator, with retries, backoff, and per-source policy applied consistently.
```
POST /v1/jobs
{ "source": "sitemap", "depth": 3 }
```
- Postgres sink with exactly-once delivery
- Faster sitemap parser, 4x throughput
- Per-source rate limiting and backoff<header class="site-header">
<nav>Home · Pricing · Docs · Blog · Changelog · Careers</nav>
<div class="search-bar"><input placeholder="Search the site..." /></div>
</header>
<div class="promo-banner">Black Friday: 30% off annual plans, ends soon →</div>
<div class="cookie-banner">We use cookies to improve your experience. <button>Accept all</button></div>
<nav class="breadcrumbs">Home / Blog / Engineering</nav>
<aside class="ad-slot" data-sponsor="true">
<iframe src="ads.example.com/slot-482"></iframe>
</aside>
<article>
<h1>Launching the new platform</h1>
<p class="byline">Posted by Jordan Avery · 8 min read · Updated 2 days ago</p>
<div class="newsletter-cta">
<h3>Enjoying this post?</h3>
<p>Subscribe for weekly engineering deep dives.</p>
<input placeholder="[email protected]" /><button>Subscribe</button>
</div>
<p>Clean, readable content. Navigation, ads, and boilerplate stripped before it reaches your pipeline.</p>
<h2>What changed</h2>
<p>Every stage of the crawl now runs through a single orchestrator, with retries, backoff, and per-source policy applied consistently.</p>
<pre><code>POST /v1/jobs
{ "source": "sitemap", "depth": 3 }</code></pre>
<ul>
<li>Postgres sink with exactly-once delivery</li>
<li>Faster sitemap parser, 4x throughput</li>
<li>Per-source rate limiting and backoff</li>
</ul>
<aside class="ad-slot" data-sponsor="true">
<iframe src="ads.example.com/slot-915"></iframe>
</aside>
<div class="related-posts">
<h3>Related reading</h3>
<a href="/blog/orchestration">Inside the orchestrator</a>
<a href="/blog/sinks">Choosing a data sink</a>
</div>
</article>
<footer class="site-footer">
<!-- 40 links, social icons, newsletter form -->
</footer>Answers before you ask.
Straightforward answers on data ownership, scale, and licensing, no sales call required.
Run the crawler on your own infrastructure.
Crawl-job orchestration is available today for enterprise self-hosting. Tell us what you're building.